80% of Anthropic's Code Is Now Written by Claude as Recursive Self-Improvement has Begun
- David Borish

- Jun 5
- 7 min read
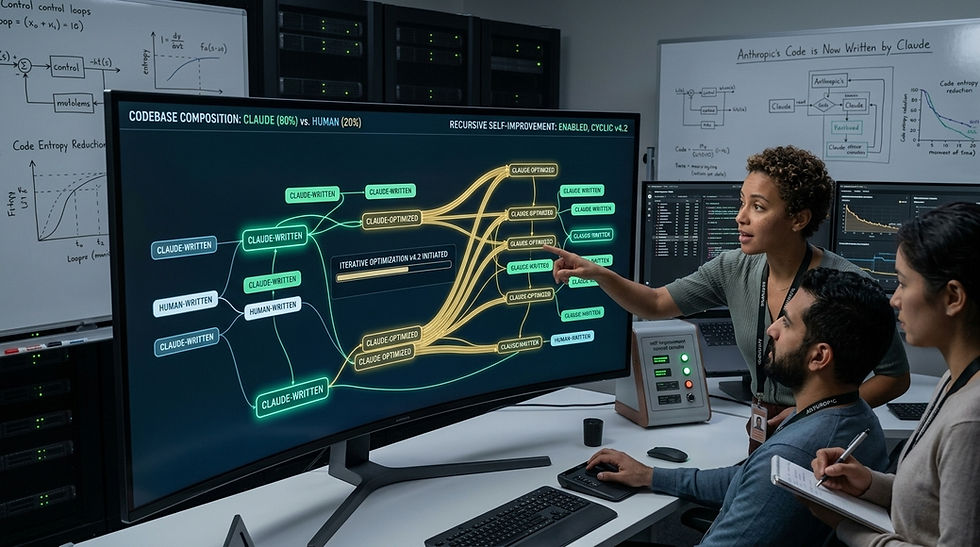
The Numbers Anthropic Is Now Sharing
Most discussions of recursive self-improvement treat it as a future event. Anthropic's new report from the Anthropic Institute repositions it as a process already underway, with internal data to illustrate how far it has progressed.
The headline figure: as of May 2026, more than 80% of code merged into Anthropic's production codebase was written by Claude. Before Claude Code launched in research preview in February 2025, that number sat in the low single digits. Engineers are now merging 8x as much code per quarter as they did during 2021 to 2024.
The report is notable for what it presents alongside the productivity numbers. Anthropic is releasing data on Claude's success rates at open-ended engineering tasks, its performance on self-defined research experiments, and its growing ability to suggest better next steps in live research sessions than the humans running them. Taken together, these metrics describe a system that has moved well past code assistant and into something closer to a collaborative research partner, one that is increasingly setting portions of its own agenda.
What the External Benchmarks Show
Before turning to internal data, the report grounds the argument in public benchmarks. The length of tasks AI systems can reliably complete autonomously has been doubling roughly every four months, an acceleration from the earlier trend of doubling every seven months.
On SWE-bench, a standard test requiring models to fix real bugs in real open-source codebases, AI performance went from low single digits to near-saturation in two years. CORE-Bench, which tests whether a model can reproduce the results of a published research paper, saw AI systems go from roughly 20% success in 2024 to saturation fifteen months later.
The METR evaluation group, which measures how long AI systems can work autonomously on tasks, found that Claude Mythos Preview could sustain reliable performance for at least 16 hours, described as being at the upper boundary of what their current evaluation tools can measure. In March 2024, Claude Opus 3 could complete software tasks that take a skilled human about four minutes. By April 2026, Claude Opus 4.6 was completing tasks that take a human 12 hours.
Inside Anthropic's Codebase
The productivity shift inside Anthropic is partly explained by a structural change in how Claude operates. Before Claude Code, engineers would receive a suggestion and manually copy it into their editor. When Claude was given the ability to write and run code itself, the slope of code output per engineer began rising. It steepened again in 2026 as models began working autonomously across longer time horizons.
Anthropic is careful to note that lines of code is an imperfect proxy for productivity, since it measures volume rather than quality. But the internal poll they conducted in March 2026, covering 130 employees across research teams, found that the median respondent estimated they were producing roughly 4x as much output using Mythos Preview as they would have without any AI assistance. The report acknowledges this figure likely overstates the real gain due to respondent bias, but describes the overall direction as consistent with other observations.
One case makes the scope of the shift concrete. In April 2026, Claude shipped over 800 fixes that reduced a class of API errors by a factor of one thousand. The engineer overseeing the work estimated a human would have needed four years to complete it. The task required holding large amounts of unfamiliar context simultaneously, something humans do poorly across months-long stretches of debugging work.
An Anthropic employee quoted in the report put it plainly: "I started leaning hard into Claudifying about a year ago. It's now been roughly five months since I last wrote any code myself."
Code Quality and the Closing Gap
Shipping volume is one part of the picture. Code quality is another, and here the report offers a more qualified assessment.
By Anthropic's description, Claude-written code was noticeably worse than human-written code in late 2025. By mid-2026, the gap had closed to rough parity. The company expects Claude-written code to be strictly better than human-written code within the year.
To manage the transition, Anthropic now uses an automated Claude reviewer to screen every proposed change to its codebase before it can be merged. A retrospective analysis found that this system would have caught approximately one-third of the bugs behind past incidents on claude.ai before they reached production. The engineers who wrote that code are, by any measure, among the more capable software engineers working on frontier AI systems.
On the most open-ended engineering tasks, where Claude is handed a live incident with minimal specification, its success rate reached 76% in May 2026, up 50 percentage points in six months.
One example: a routine dependency upgrade began crashing tens of thousands of training jobs. Claude was given access to the cluster and a brief description of the problem. Working through live jobs and testing environment configurations, it isolated the obscure debugging flag triggering the crash, confirmed a fix, and closed the incident in two hours. A human would typically spend two to three days on comparable work.
The Research Side: Experiment Execution to Experiment Design
The more consequential data in the report concerns AI performance on research, not just engineering.
Anthropic runs a recurring internal test with each model release: give Claude code that trains a small AI model and ask it to make the training run as fast as possible. The goal and success criteria are fixed in advance; Claude's job is to find speedups by rewriting, running, timing, and repeating. A skilled human researcher would need four to eight hours to achieve roughly a 4x improvement over the starting code. In May 2025, Claude Opus 4 averaged a 3x speedup. By April 2026, Claude Mythos Preview was achieving 52x.
The report is transparent about what this does and does not measure. The absolute multiple depends on how much room for improvement exists in the starting code. What it does reveal, on a consistent experimental setup, is both the cross-model trajectory and the gap relative to skilled human performance. On this particular type of research task, within a clearly specified experiment, AI performance has crossed from helpful to better than human.
In April 2026, Anthropic published its first demonstration of Claude running an open-ended research project end to end. Agents were given an unsolved AI safety question: can a weaker model reliably supervise a stronger one? The agents proposed hypotheses, ran experiments, shared findings with parallel agents, and iterated. Two human researchers, working for about a week, recovered roughly 23% of the performance gap between floor and ceiling on this problem. The agents recovered 97%, using roughly 800 cumulative compute-hours and $18,000 in compute. Humans chose the problem and wrote the scoring rubric. The agents designed every experiment themselves.
A separate evaluation looked at 129 real Claude Code sessions from January through March 2026, specifically selecting moments where a human researcher had taken a detour that sent the investigation sideways. Various Claude models were shown only the work before the detour and asked what they would do next. In November 2025, the best available model beat the human's choice 51% of the time. By April 2026, Mythos Preview was doing so 64% of the time.
The Tony Hawk Paradox Plays Out in Real Time
Readers familiar with the Tony Hawk Paradox will recognize the pattern here. The full cycle of AI-accelerated AI development, from code generation to experiment execution to research direction-setting, appeared first inside the controlled environment of a frontier AI lab before becoming a dynamic that will eventually operate across the broader economy. Anthropic's engineers are the test population. Their workflow describes what is coming for technical knowledge workers more generally, though on a compressed timeline that most organizations are not yet tracking.
The report describes three forward scenarios. In the first, the current capability curves bend into S-curves, diminishing returns set in, and today's AI becomes widely diffused without crossing the threshold of full autonomous self-improvement. In the second, efficiency gains compound but humans retain direction-setting authority, enabling small organizations to operate with the output of much larger ones. In the third, AI systems become capable of fully autonomous recursive self-improvement and begin designing their own successors, with humans shifting primarily to oversight and verification.
Anthropic states clearly that it views the first scenario as unlikely based on current evidence. It sees the second as the near-term trajectory already in motion. The third is treated seriously rather than speculatively.
What Stays Human, and for How Long
The report identifies research taste and judgment as the remaining human advantage: choosing which problems matter, deciding which results to trust, and recognizing when an approach has run out of road.
But even this is framed carefully. The early evidence on Claude's improving research judgment is described as narrow and preliminary, while noting that many capabilities now considered intuitive, including AI systems explaining humor, demonstrating theory of mind, and solving linguistic problems, followed the same pattern of failing for a time and then getting good.
An Anthropic employee's observation cuts close to the practical reality: "The comparative advantage of humans as of right now is still in seeing the bigger picture and thinking beyond the confines of the immediate task."
That framing invites a follow-on question the report does not answer: how long does that comparative advantage hold?
On Coordination and Deliberate Slowdown
The report closes with a section on what should be done, which covers territory that most technical documents avoid.
Anthropic states that it believes the option to slow or temporarily pause frontier AI development would likely be good for the world, while acknowledging that a unilateral pause by one lab would primarily change who leads, not whether development continues. A credible multilateral pause would require verification mechanisms that do not currently exist, because AI training runs are far easier to conceal than the physical infrastructure involved in other arms control regimes.
The Anthropic Institute commits to organizing conversations with policymakers, researchers, civil society, and other AI companies in the coming months. It will publish what comes out of them.
The window for that kind of deliberation is open now. The report's own data describes how quickly it could close.